
A small group of determined and like-minded people can change the course of history-Mahatma GandhiTidak segala hal bisa kita lakukan seorang diri, senyaman apapun kita dengan kesendirian, saya yakin ada saat dimana kita berharap tidak ingin sendiri. Kadang hidup berkelompok membuat kita paham bahwa banyak hal yang bisa dilakukan bersama tanpa harus takut dengan kegagalan. By the way, pada postingan kali ini, saya kembali akan berbagi ilmu yang tidak seberapa ini, dengan harapan dapat meng- enlightening khazanah keilmuan kalian seputar data mining. Mana tau nih ya, adik-adik mahasiswa lagi galau mikirin judul krispi eh skripsi maksud saya. Apa lagi yang fokus pada tema data mining. Kudu pada belajar ya kan *hehehehehe.
Jika postingan sebelumnya saya sudah membahas tentang Algoritma Apriori (baca disini!), maka pada kesempatan kali ini saya akan mengulas tentang algoritma K-means Clustering. Here we go !!
Cluster adalah kumpulan record yang mirip satu sama lain dan berbeda dengan record di cluster lain. Clustering itu sendiri mengacu pada proses pengelompokan record, hasil pengamatan atau pun kasus-kasus tertentu ke dalam kelas-kelas yang memiliki kesamaan. Sementara itu, clustering berbeda dengan klasifikasi, karena pada clustering tidak ada variabel target untuk pengelompokan. Sebagai tambahan, tugas dari clustering itu sendiri bukan untuk mengklasifikasikan, memperkirakan, atau memprediksi nilai variabel target. sebaliknya, Clustering berusaha untuk mengelompokkan seluruh data yang ditetapkan ke dalam subgruop atau kluster yang relatif homogen, di mana kesamaan record di dalam kluster dimaksimalkan dan kemiripan dengan catatan di luar kluster ini diperkecil.
K-Means Clustering
K-Means Clustering merupakan algoritma yang efektif untuk menentukan cluster dalam sekumpulan data, di mana pada algortima tersebut dilakukan analisis kelompok yang mengacu pada pemartisian N objek ke dalam K kelompok (Cluster) berdasarkan nilai rata-rata (means) terdekat.
Adapun tahapan algoritma ini adalah sebagai berikut :
Pertama, tentukan berapa banyak jumlah k (cluster)
Kedua, secara acak tentukan record yang menjadi lokasi pusat cluster.
Ketiga, temukan pusat cluster terdekat untuk setiap record. Adapun persamaan yang sering digunakan dalam pemecahan masalah dalam menentukan jarak terdekat adalah persamaan Euclidean berikut :

Dimana x=x1,x2,x3……xm dan y=y1,y2,y3…ym, sementara m menyatakan banyaknya nilai atribut dari 2 buah record.
Keempat, tentukan cluster terdekat untk setiap data dengan membandingkan nilai jarak terdekat, lalu perbaharui nilai pusat clusternya.

Kelima, ulangi langkah 3 sampai 5 hingga tidak ada record yang berpindah cluster atau convergen.
Pusing ? Calm down guys !!, Untuk memudahkan pemahaman kita tentang tahapan di atas, saya akan berikan contoh. Berikut terdapat 8 record yang akan menjadi dataset kemudian dataset tersebut akan kita gunakan dalam membantu memahami penerapan algoritma k-means clustering.

Langkah Kedua, tetapkan 2 record dari dataset sebagai titik pusat cluster.
M1 : {1,1} -> Titik pusat Cluster pertama (C1)Langkah ketiga, tentukan pusat cluster terdekat untuk setiap record dari dataset
M2 : {2,1} -> Titik pusat Cluster kedua (C2)
Nah, untuk tahap ini kita akan menggunakan persamaan Euclidean untuk menentukan jarak setiap record dengan pusat cluster.

Dan dihitung seterusnya hingga data paling akhir (data ke 8), sehingga diperoleh rekap hasil perhitungan jarak terdekat ke setiap cluster sebagai berikut :

Langkah Keempat, tentukan cluster(kelompok) setiap record dan perbaharui titik pusat cluster.

Setelah cluster(kelompok) untuk setiap record ditentukan seperti pada tabel di atas, tugas kita sekarang adalah memperbaharui nilai titik pusat cluster, yang mana sebelumnya titik pusat cluster kita adalah M1{1,1} dan M2{2,1}. Untuk meng-update nilai titik pusat cluster, kita dapat menggunakan persamaan cluster center sebagai berikut :

Maka titik pusat cluster terbaru adalah sebagai berikut :

Setelah didapat nilai update titik pusat cluster, selanjutnya kita akan mengulangi langkah ketiga, guna menentukan kembali kelompok tiap data. Untuk menguji apakah terjadi perpindahan kelompok pada data tersebut. So, setelah di hitung kembali didapatlah hasil nilai terdekat tiap kelompok sebagai berikut.

sementara untuk penentuaan kelompok dapat dilihat pada tabel di bawah ini

Setelah dilakukan penentuan cluster yang baru, sesuai dengan titik pusat cluster yang diupdate sebelumnya, ditemukan adanya 1 data yang berpindah kelompok, yang mengakibatkan pengelompokan pada iterasi pertama ini belum konvergen, sehingga harus dilakukan penentuan kelompok kembali pada iterasi kedua dengan nilai titik pusat cluster yang harus diupdate ulang.

Adapun hasil pengelompokan setelah melakukan ulang langkah 3 dan langkah 4 adalah sebagai berikut :

Pada iterasi 2, tidak terjadi perpindahan kelompok pada setiap data, dengan ini maka pengelompokan sudah dinyatakan konvergen atau sudah dianggap optimal.
sebenarnya, inti dari terjadinya banyak iterasi adalah pada saat pemilihan acak titik pusat cluster di awal, sebaiknya pilihlah titik pusat cluster yang memiliki selesih yang cukup jauh agar tidak banyak iterasi yang terbentuk, selain itu pastikan juga bahwa titik pust cluster benar-benar menggambarkan atau mewakili kelompok data yang ingin dikelompokan.
finally, semoga postingan saya kali ini bermanfaat untuk teman-teman semua, and do not hesitate to ask me about this sharing post !! see ya !!
sebenarnya, inti dari terjadinya banyak iterasi adalah pada saat pemilihan acak titik pusat cluster di awal, sebaiknya pilihlah titik pusat cluster yang memiliki selesih yang cukup jauh agar tidak banyak iterasi yang terbentuk, selain itu pastikan juga bahwa titik pust cluster benar-benar menggambarkan atau mewakili kelompok data yang ingin dikelompokan.
finally, semoga postingan saya kali ini bermanfaat untuk teman-teman semua, and do not hesitate to ask me about this sharing post !! see ya !!

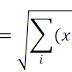

{kind=link}
1 Comments
Hai.. saya 2 persoalan.
ReplyDeletePertama, bagaimana anda tentukan CLUSTER pada langkah 4?
Kedua, saya keliru pada step iterasi 1 dengan clustercenter yang baharu. Saya cuba step anda dan dapati hasil yang sedikit berbeza pada C1 dan C2 yang baharu...
Harap tuan dapat memberikan penjelasan.
Terima kasih
Jangan Lupa Tinggalkan Komentar, Mohon berkomentar yang positif.